05 Feb 2017
Should I get started with “Machine Learning” to improve my situation?
If you are trying to pick an action based on a problem you are facing, how should you approach it? You have heard a lot or a little about “Machine Learning.” Here’s my personal story to help you decide.
As a software programmer, when I want solve a problem, I try to figure out a way to automate it. Being a machine learning engineer, I begin comparing to the oldest problem solving method: deterministic programming.

Being active is my passion. Everyday, I decide whether to go outside for a run outdoors. Situations that influence my decision are:
-
Is it raining outside?
- Yes –> Don’t run
- No –> I think I can run.
-
Time of the day?
- Is it 10 P.M to 5 A.M –> Dont’ run. Too dark outside.
- 5 A.M to 7 A.M –> I think I can run.
- 8 A.M to 9 A.M –> Am I working from home? I think I can run.
- 9-5 P.M –> Don’t run. Office work.
- 5 P.M -7 P.M –> I think I can run.
- 7 P.M - 9 P.M –> if it is not too dark then I can run.
- 9 P.M - 10 P.M –> After dinner, I don’t run.
-
Do I have to drop my son in school?
- Is it Morning school drop time ( 8.30 A.M to 9 A.M) –> Dont run
- Is it evening school pickup time (4.45 P.M to 5.15 P.M) –> Dont run.
- Other times. I think I can run.
-
What is the temperature outside?
- 50-80F –> I think I can run.
- 80F-110F –> I don’t think I can run. Too hot.
- 0F - 50F –> I am not running.
If I do this deterministically, then I will end up with lot of “If” conditions for all the permutations of combinations that are possible . With just 4 attributes, it is getting complex. Imagine having hundreds of attributes influencing whether I want to run or not. This is where machine learning will save my day. (Did I mention that I am a lazy programmer? Good code is better than more code.).
A machine learning model “projects past on future” to “learn” whether I will run outside or not. With historical data of my running (Map my run, Garmin, Fitbit, Apple Watch) + publicly available weather data, I can train a machine learning model (classification problem) to decide whether I want to run or not. A set of machine learning algorithms will approximate a decision boundary for this problem. Output from the machine learning algorithm is probability for 2 classes: a) run or b) don’t run.
Do you see? Machine learning rocks. This story is perfect for a supervised classification problem.
22 Jan 2017
Natural Language Processing is a complicated area. Computers are really good at crunching numbers but not so much with text. We have to specifically instruct them on how to handle text. For Text analytics to be carried out we have to represent text in a form the computers can understand i.e. in the form of numbers.
- The method for doing this varies.
- A good method is one that captures as much of the meaning of the text as possible.
After this is done, analysis can be carried out on these numbers in the same way as dealing with numbers.
Conventional Text Analysis or Bag of Word Models
Lets take this example text “SanFrancisco is a beautiful California city. LosAngeles is a lovely California metropolis”
Popular way of converting this text to numbers is known as “Bag of Words” model. Each word is extracted from the text and put in a bag together.Each word in the bag is then assigned a suitable value. Lets parse the example text and extract words
“SanFrancisco”, “is”, “a”, “city”, “LosAngeles” ,”lovely”, “California”, “metropolis”.
Stop words are the most common words in a language. In the extracted list of words “is” , “a” are considered stop words hence it will be ignored. So the final list of extracted words will be
“SanFrancisco”, “beautiful”, “city” ,”LosAngeles”, “lovely” , “California” , “metropolis”
In Bag of Words model each word is assigned a value based on number of times it occurs in the text.
| SanFrancisco |
beautiful |
city |
LosAngeles |
lovely |
California |
metropolis |
| 1 |
1 |
1 |
1 |
1 |
2 |
1 |
This approach has lot of disadvantages, few of those are listed below
- It does not capture the order of words in the original text.
- It does not capture the context of the text.
- It does not capture about the meanings of the words.
What we are telling the computer using this approach is city, lovely, metropolis are all equal. Even though city and metropolis are equivalent and lovely is something very different.
Neural Language models
Prof Yoshua Bengio started this work in 2008. A language model is an algorithm for capturing the salient statistical characteristics of the distribution of sequences of words in a natural language.
A neural language model learn distributed representations on words to reduce the impact of the curse of dimensionality. Curse of dimensionality is when number of input variable grows the number of required examples to train a model grows exponentially.
You can read more about this work in this link
Word2vec – Word to Vector
Word2Vec is one of the influential papers in Natural Language Processing. It has nearly 3000 citations. Word2Vec improves on Prof Yoshua Bengio’s earlier work on Neural Language Models. Word2Vec was created by google, with main author being Tomas Mikolov. You can read the original paper here.
Word2vec is an answer to all the disadvantages listed in the previous section.
- It is intelligent, learns context of the text.
- Understands sentences, and not just individual words.
- Understands relationships between words.
We understand what a word is, lets see what a vector is. A vector is a sequence of numbers that forms a group. For example
- (3) is a one dimensional vector.
- (2,8) is a two dimensional vector.
- (12,6,7,4) is a four dimensional vector.
A vector can be represented as by plotting on a graph. Lets take a 2D example
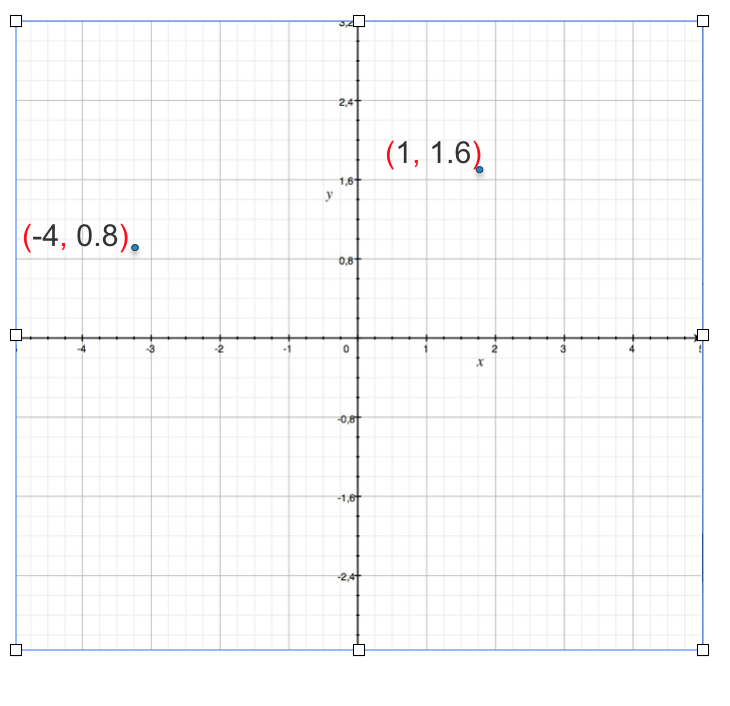
We can only 3 dimensions, anything more than that you can just say it not visualize.
How Word2Vec works
For a input text it looks at each word and the context of words around it. It trains on the text, and recognizes the order of each word, and the structure of the sentences. At the end of training each word is represented by a vector of N (mostly in 100 to 300 range) dimension.
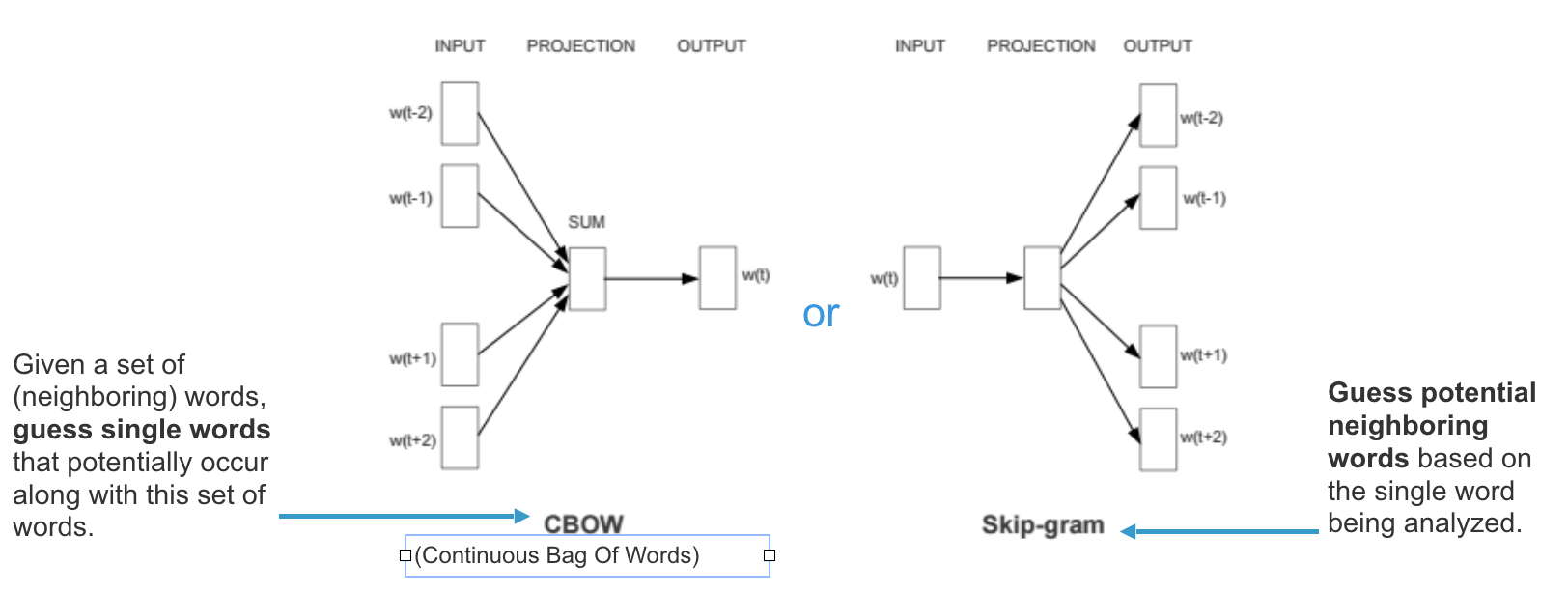
When we train word2vec algorithm in the example discussed above “SanFrancisco is a beautiful California city. LosAngeles is a lovely California metropolis”
Lets assume that it outputs 2 dimension vectors for each words, since we can’t visualize anything more than 3 dimension.
- SanFrancisco (6,6)
- beautiful (-13,-4)
- California (10,8)
- city (2,10)
- LosAngeles (6.5,5)
- lovely(-12,-7)
- metropolis(2.5,8)
Below is a 2D Plot of vectors
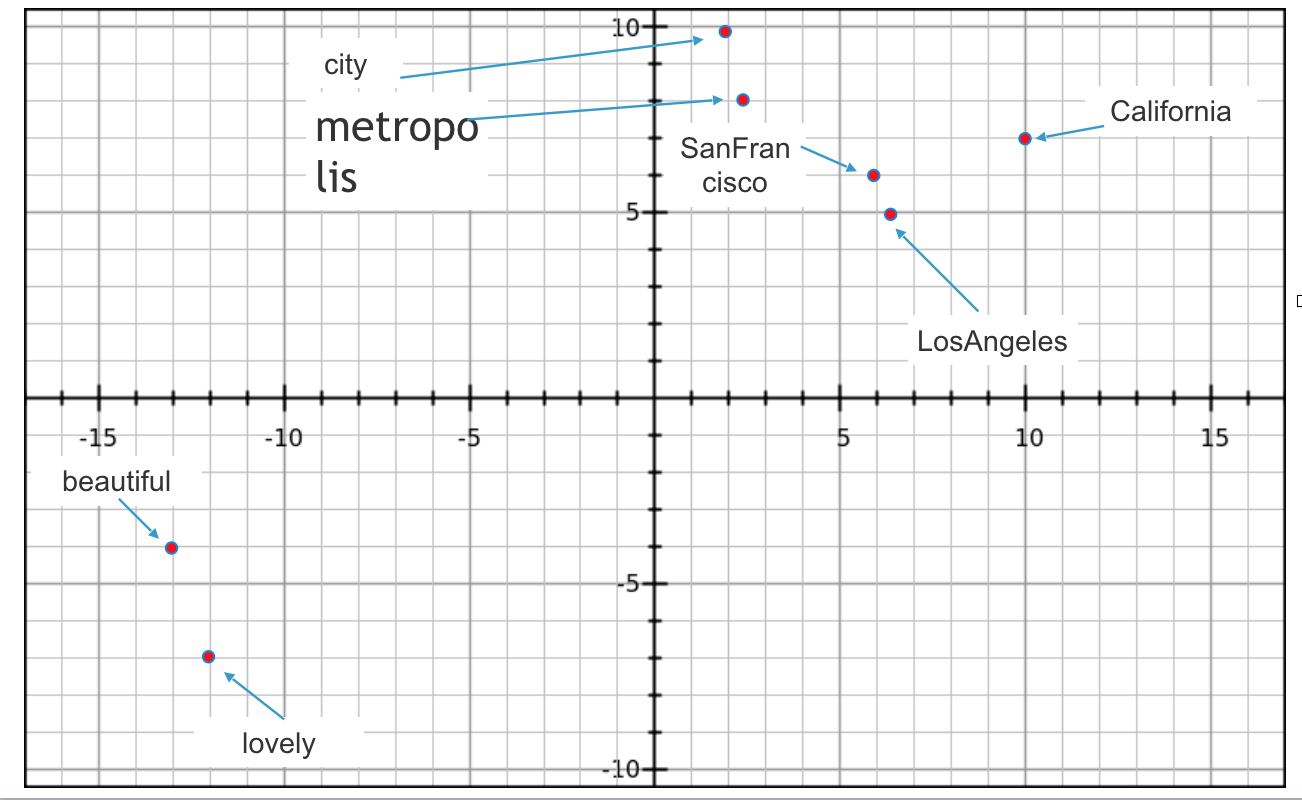
You can see in the image that Word2vec algorithm inferred from the input text. SanFrancisco and LosAngeles are grouped together. Beautiful and lovely are grouped together. City and metropolis are grouped together. Beauty about this is, Word2vec deduced this purely from data, without being explicitly taught english or geography.
Word2vec and Analogies
Word2vec algorithm is really good in discovering analogies on data. In the below plot from relative position analogies can be observed.
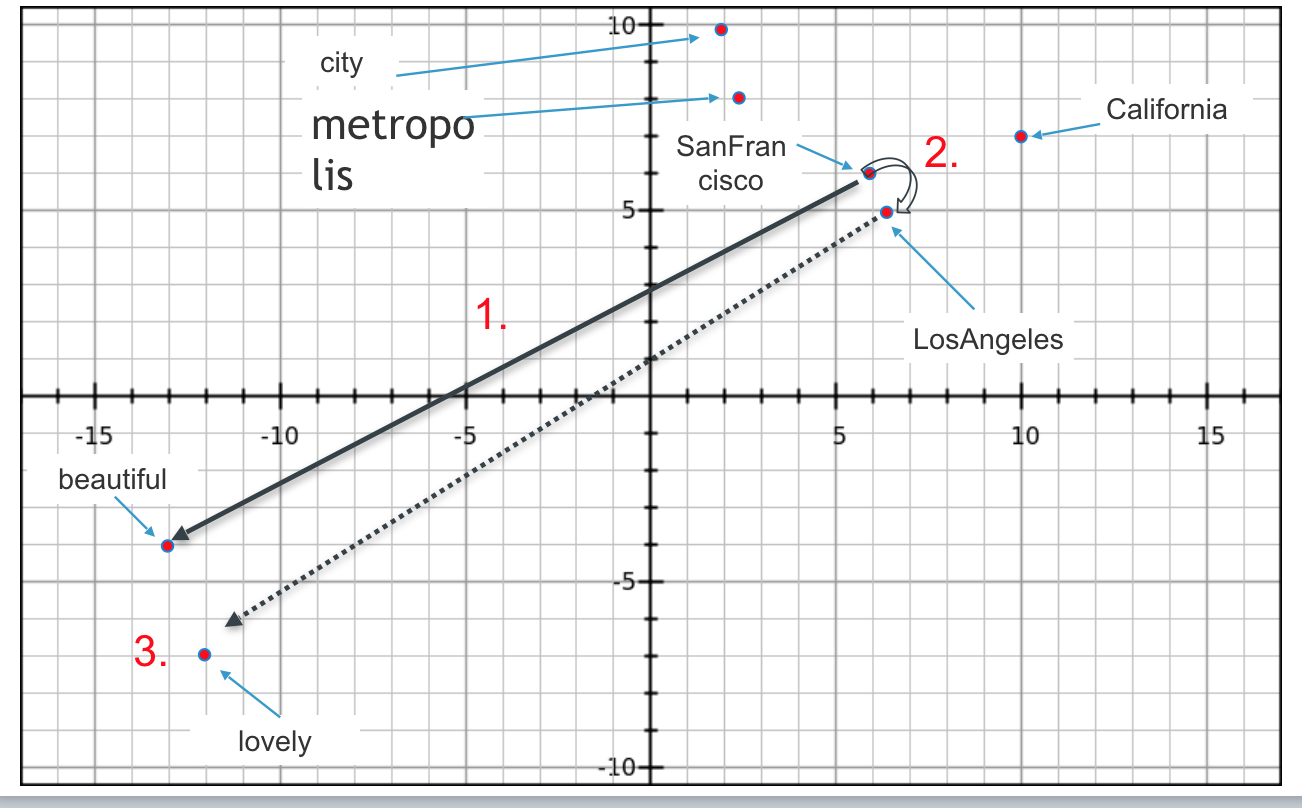
Algorithm knows the answer to
- If SanFrancisco : beautiful
- then LosAngeles : ???
Answer : lovely
To get to the answer do
- Draw a line from SanFrancisco to beautiful
- Shift this line to LosAngeles
- Find the end-point of this line.
Similarly you can draw other analogies like
- if SanFrancisco : city
- then LosAngeles : metropolis
Math for Analogies is beautiful, it can be expressed in simple vector arithmetic.
- SanFrancisco - LosAngeles = beautiful - [unknown]
- [unknown] = beautiful + LosAngeles - SanFrancisco
- [unknown] = (-12.5,5) which is close to lovely

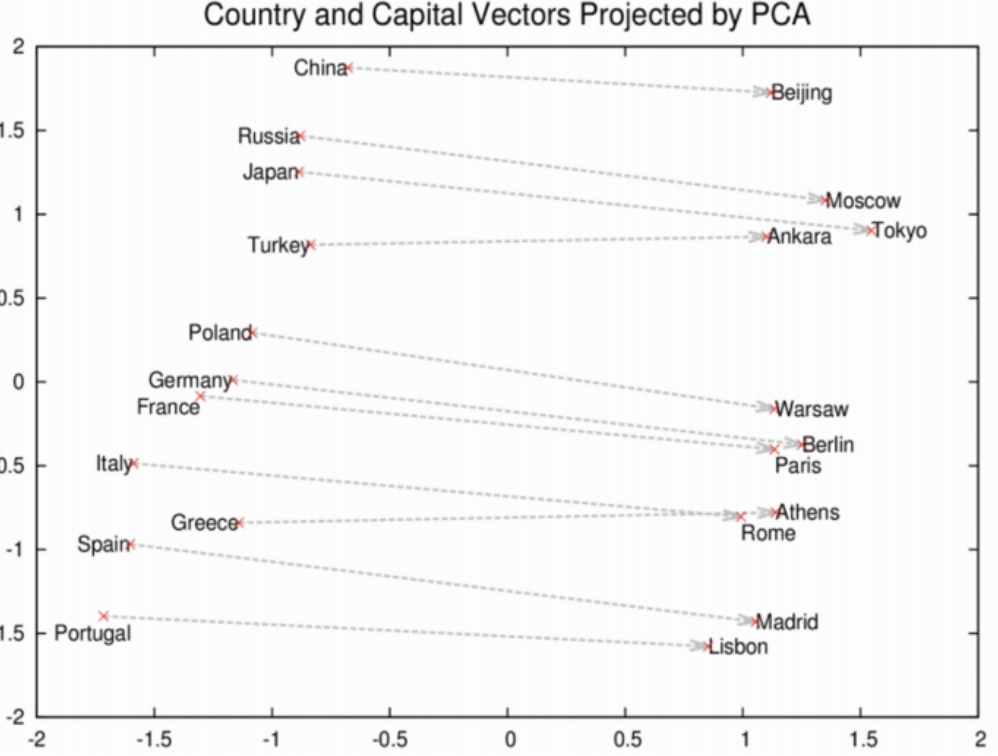
Google trained Word2Vec on a large volume data, it came up with some interesting analogies
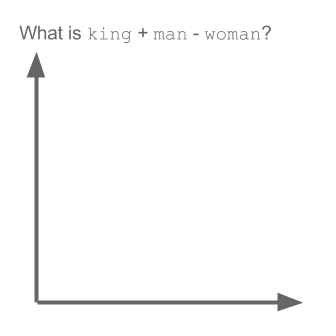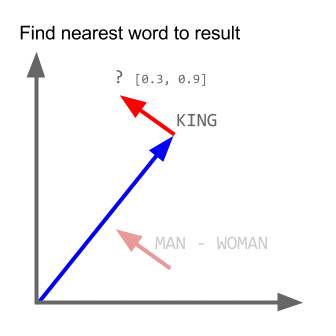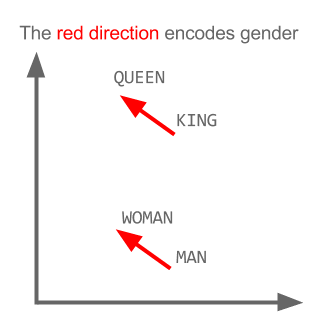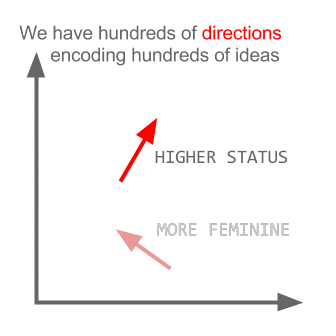
countries and capitals
Word2vec depicting relationships between countries and capitals
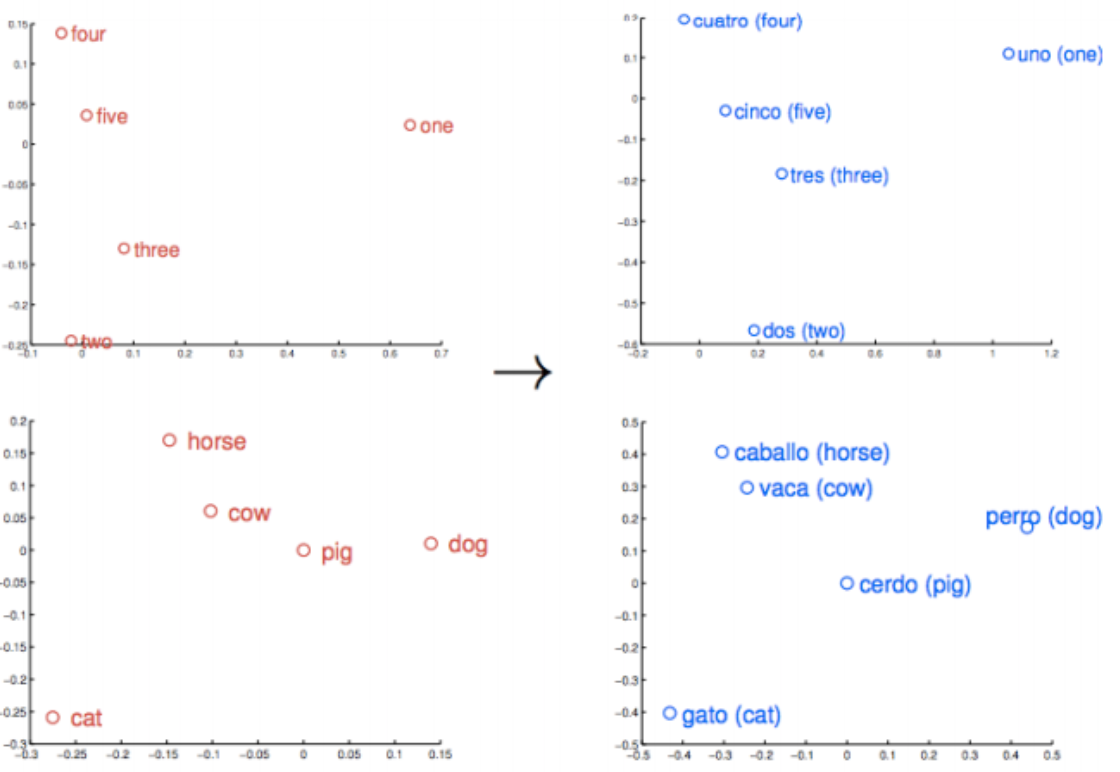
Machine translation
In complicated use-cases models can understand translations from one language to another.
Contributions
Thanks to Arthur Chan for suggesting changes to the blog.
Further Reading
22 Jan 2017
DeepLearning is a verstaile tool to solve problems that cannot be solved using traditional programming approach. I am a CTO at Datalog.ai where we solve lot of cool problems using Deep Learning. ML Researchers and Engineers use lot of Deep Learning packages like Theano, Tensorflow, Torch, Keras etc. Packages are really good but when you want to get an understanding on how Deep Learning works, it is better to go back to basics and understand how it is done. This blog is at an attempt at that, it is going to be a 3 part of series with topics being
- DeepLearning using Numpy
- Why TensorFlow/Theano not Numpy?
- Why Keras not TensorFlow/Theano?
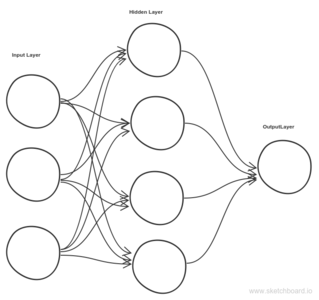
Deep learning refers to artificial neural networks that are composed of many layers like the one shown above. Deep Learning has many flavor’s like Convolution Neural Networks, Recurrent Neural Networks, Reinforcement Learning, Feed Forward Neural Network etc. This blog is going to take the simplest of them, Feed Forward Neural network as an example to explain.
Machine Learning deals with lot of Linear Algebra operations like dot product, transpose, reshape etc. If you are not familiar with it, I would suggest refer to my previous blog post in All about Math section.
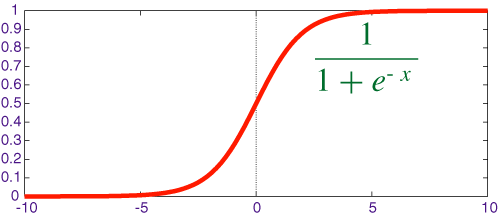
Deep Learning needs an activation function to squish real numbers to probability values between 0 and 1 , there are different activation functions like sigmoid, Tanh, RELU etc. For this toy example i have used sigmoid activation function.
We are going to use Gradient Descent to find optimal parameters to solve for Y. Gradient descent uses the derivative of the sum of errors to update the systems parameters a little bit in such a way that the error decreases as much as possible.After every update the system learns to predict with a lower error. Let it run many iterations and it will converge at some optima(local). Sigmoid function takes a parameter to calculate Derivative. Don’t worry if you don’t understand this explanation, it is very intuitive if you can follow the code along. If you are looking for more explanation refer to this video by Prof Andrew Ng.
For this example on Numpy Deep Learning Code, I am going to use a synthetic dataset. Output is the target we are going to predict.
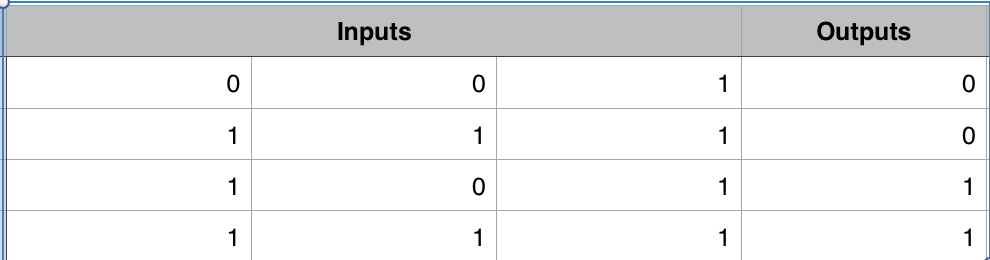
Randomly initialize weights for 2 synapses. Synapses 0 will be of shape 3x4, Synapses 1 will be of shape 4x1
With Gradient descent you have to run the process for n number of iterations, in ML lingo it is called epoch (since it will take ages to complete). In our case we are going to run it for 50 iterations. Since this is a 1 hidden Layer network, we do a dot product between input l0 and synapses_0 and then squish it using sigmoid function. Pass output of l1 as input to hidden layer and do dot product between l1 and synapses_1 weights and then squish it using sigmoid function.
Now we are off to calculate what is the error for our prediction for l2 layer. Then use derivative to find out how much we should update our Synapses 1.
Same step should be done for l1 layer, but error should be calculated based on how much we are off on l2.
Update weights for synapses_0 and synapses_1 based on calculated l1_delta and l2_delta respectively.
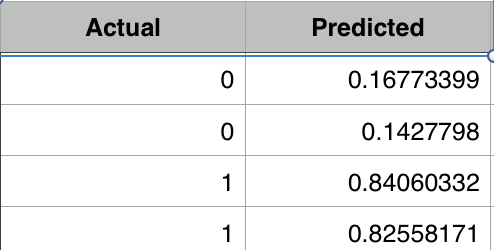
See below on how loss is decreasing for each iteration.
With just 50 iterations we are very close to actual value
Siraj Raval has a really good youtube video on Intro to Deep Learning check it out too.
17 Jan 2017
I oscillated between different blogs and videos to become a deep learning practitioner. This blog is to document my learning and to follow an optimal path to become Deep Learning practioner faster
It is all about Math
Don’t be shy if you haven’t brushed your Math skills for a while. When you are programming for while bad habits creep in , it takes time to unlearn and learn new things. I had a tough time initially then started refreshing my Math again. I used Khan academy , i like how most of the sessions are only 10 minutes long. I followed below order
- Algebra – Yes you have to refresh Algebra. Remember the equation for straight line y = mx + b. That is the best equation you learned in your life. Most of machine learning is about finding the value of “m” called weights and “b” called biases.
- Trigonometry
- Differential Calculus – Machine Learning/Deep Learning is all about finding slope aka derivatives, hence do it thoroughly
- Partial Differential Equations
- Integral Calculus
- Probability and Statistics – this is important for anything in Machine Learning.
- Linear Algebra – Most of calculations are done using Matrix multiplication, dot products, transpose so learn this well.
- Linear Algebra Advanced – Yes it is that important. I referred to Prof Gilbert Strang lectures from MIT.
Intro into Machine Learning
I took Prof Andrew Ng’s Coursera Machine Learning course in 2012. It is the bible if you are starting with Machine Learning. Take your time and learn the basics.
Mining Massive Datasets
This was one of the best courses i took, it helped me to understand Mathematical intuition behind lot of Machine Learning algorithms.
Deep Learning
This course is Math heavy, but Prof Ali Ghodsi lectures explains it well. It is one of the hidden gems there are quite a series of lectures in youtube, watch it all. Watch it in loop, till you get hang of every concept.
Convolution Neural Networks
Convolution Neural networks is a class of Deep Learning that is predominantly used for computer vision. AndreJ Karpathy and Justin Johnson taught a great course cs231n in Stanford on CNN. It gives lot of practical tips on building Deep Learning models.
I wrote an intro level CNN tutorial for Keras.
Natural Language processing
Richard Socher’s class on Natural Language processing is must if you want to work on Unstructured text. CS224d is heavy on Recurrent Neural Networks. Recently Convolution Neural Networks are being used more for NLP.
Learn Python
Python is becoming a de-facto language for scientific and numerical computation. Most Deep Learning libraries have a python front end. If you are new to python then use Byte of Python book to learn. There are lot of good youtube tutorials too.
GPU’s
If you have managed to take all these classes mentioned in the list above, then you are a serious about being a Deep Learning practitioner. Invest in a good NVIDIA GPU for trying out different models. You can use AWS for training but you will end up spending lot of money to train different models, in a long run it will make sense to buy your own hardware. Hey you can use it for gaming too, if you feel bored about Deep Learning.
Must Buy/Read Books
Ian GoodFellow, Aaron CourVille, and Yoshua Bengio wrote an awesome Deep Learning Book. I bought it, since it is a text-book theory book.
Another book i often referred to is Neural Networks and DeepLearning. This book explains [Backpropagation]((http://neuralnetworksanddeeplearning.com/chap2.html), one of the most important concepts in deep learning very well.
Blogs to Read
I read Machine Learning Mastery, it has practical tips and good blogs.
Deep Learning Frameworks
There are quite a few options when it comes to Deep Learning frameworks
- Tensorflow
- Theano
- Keras
- Caffe
- CNTK
- Lasagne
- Other
I am personally big fan of Keras (wrapper over Tensorflow and Theano), since it abstracts lot of complexity of building a Deep Learning model, i can build a model and test whether it works or not very fast. There are tons of online tutorials on Tensorflow and Theano.
Gokul Krishnan wrote a really good blog on Anatomy of Deep Learning Frameworks
Kaggle
Kaggle is a data science competition forum, lot of researchers compete there and share their approach they used for solving that problem. Compete actively to learn and improve.
I used twitter recommendation engine (learning machine learning using machine learning) to keep myself updated with latest research papers. Check whom i am following , on my Twitter