Chunking
05 Aug 2024Breaking Down Data: The Science and Art of Chunking in Text Processing & RAG Pipeline
As the field of Natural Language Processing (NLP) continues to evolve, the combination of retrieval-based and generative models has emerged as a powerful approach for enhancing various NLP applications. One of the key techniques that significantly improves the efficiency and effectiveness of Retrieval-Augmented Generation (RAG) is chunking. In this blog, we will explore what chunking is, why it is important in RAG, the different ways to implement chunking, including content-aware and recursive chunking, how to evaluate the performance of chunking, chunking alternatives, and how it can be applied to optimize NLP systems.

What is Retrieval-Augmented Generation (RAG)?
Before diving into chunking, let’s briefly understand RAG. Retrieval-Augmented Generation is a framework that combines the strengths of retrieval-based models and generative models. It involves retrieving relevant information from a large corpus based on a query and using this retrieved information as context for a generative model to produce accurate and contextually relevant responses or content.
What is Chunking?
Chunking is the process of breaking down large text documents or datasets into smaller, manageable pieces, or “chunks.” These chunks can then be individually processed, indexed, and retrieved, making the overall system more efficient and effective. Chunking helps in dealing with large volumes of text by dividing them into smaller, coherent units that are easier to handle.
Why Do We Need Chunking?
Chunking is essential in RAG for several reasons:
Efficiency
- Computational cost: Processing smaller chunks of text requires less computational power compared to handling entire documents.
- Storage: Chunking allows for more efficient storage and indexing of information.
Accuracy
- Relevance: By breaking down documents into smaller units, it’s easier to identify and retrieve the most relevant information for a given query.
- Context preservation: Careful chunking can help maintain the original context of the text within each chunk.
Speed
- Retrieval time: Smaller chunks can be retrieved and processed faster, leading to quicker response times.
- Model processing: Language models can process smaller inputs more efficiently.
Limitations of Large Language Models
- Context window: LLMs have limitations on the amount of text they can process at once. Chunking helps to overcome this limitation.
In essence, chunking optimizes the RAG process by making it more efficient, accurate, and responsive.
Different Ways to Implement Chunking
There are various methods to implement chunking, depending on the specific requirements and structure of the text data. Here are some common approaches:
-
Fixed-Length Chunking: Divide the text into chunks of fixed length, typically based on a predetermined number of words or characters.
def chunk_text_fixed_length(text, chunk_size=200, by='words'): if by == 'words': words = text.split() return [' '.join(words[i:i + chunk_size]) for i in range(0, len(words), chunk_size)] elif by == 'characters': return [text[i:i + chunk_size] for i in range(0, len(text), chunk_size)] else: raise ValueError("Parameter 'by' must be either 'words' or 'characters'.")text = "The process is more important than the results. And if you take care of the process, you will get the results." word_chunks = chunk_text_fixed_length(text, chunk_size=5, by='words') character_chunks = chunk_text_fixed_length(text, chunk_size=5, by='characters')print(word_chunks) ['The process is more important', 'than the results. And if', 'you take care of the', 'process, you will get the', 'results.']print(character_chunks) ['The p', 'roces', 's is ', 'more ', 'impor', 'tant ', 'than ', 'the r', 'esult', 's. An', 'd if ', 'you t', 'ake c', 'are o', 'f the', ' proc', 'ess, ', 'you w', 'ill g', 'et th', 'e res', 'ults.'] -
Sentence-Based Chunking: Split the text into chunks based on complete sentences. This method ensures that each chunk contains coherent and complete thoughts.
import nltk nltk.download('punkt') def chunk_text_sentences(text, max_sentences=3): sentences = nltk.sent_tokenize(text) return [' '.join(sentences[i:i + max_sentences]) for i in range(0, len(sentences), max_sentences)]text = """Natural Language Processing (NLP) is a fascinating field of Artificial Intelligence. It deals with the interaction between computers and humans through natural language. NLP techniques are used to apply algorithms to identify and extract the natural language rules such that the unstructured language data is converted into a form that computers can understand. Text mining and text classification are common applications of NLP. It's a powerful tool in the modern data-driven world."""sentence_chunks = chunk_text_sentences(text, max_sentences=2) for i, chunk in enumerate(sentence_chunks, 1): print(f"Chunk {i}:\n{chunk}\n")Chunk 1: Natural Language Processing (NLP) is a fascinating field of Artificial Intelligence. It deals with the interaction between computers and humans through natural language. Chunk 2: NLP techniques are used to apply algorithms to identify and extract the natural language rules such that the unstructured language data is converted into a form that computers can understand. Text mining and text classification are common applications of NLP. Chunk 3: It's a powerful tool in the modern data-driven world. -
Paragraph-Based Chunking: Divide the text into chunks based on paragraphs. This approach is useful when the text is naturally structured into paragraphs that represent distinct sections or topics.
def chunk_text_paragraphs(text): paragraphs = text.split('\n\n') return [paragraph for paragraph in paragraphs if paragraph.strip()]paragraph_chunks = chunk_text_paragraphs(text) for i, chunk in enumerate(paragraph_chunks, 1): print(f"Paragraph {i}:\n{chunk}\n")Paragraph 1: Natural Language Processing (NLP) is a fascinating field of Artificial Intelligence. Paragraph 2: It deals with the interaction between computers and humans through natural language. Paragraph 3: NLP techniques are used to apply algorithms to identify and extract the natural language rules such that the unstructured language data is converted into a form that computers can understand. Paragraph 4: Text mining and text classification are common applications of NLP. It's a powerful tool in the modern data-driven world. -
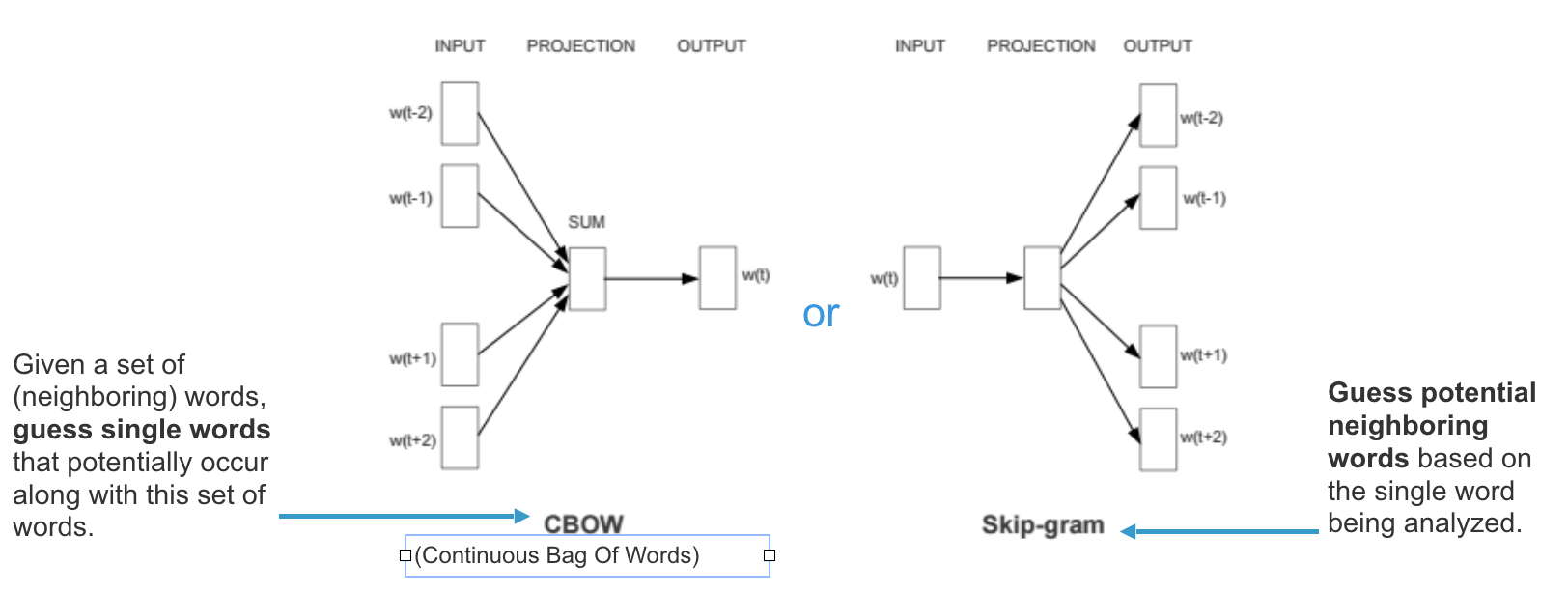
Thematic or Semantic Chunking: Use NLP techniques to identify and group related sentences or paragraphs into chunks based on their thematic or semantic content. This can be done using topic modeling or clustering algorithms.
import nltk from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.cluster import KMeans nltk.download('punkt') def chunk_text_thematic(text, n_clusters=5): sentences = nltk.sent_tokenize(text) vectorizer = TfidfVectorizer(stop_words='english') X = vectorizer.fit_transform(sentences) kmeans = KMeans(n_clusters=n_clusters, random_state=42).fit(X) clusters = kmeans.predict(X) chunks = [[] for _ in range(n_clusters)] for i, sentence in enumerate(sentences): chunks[clusters[i]].append(sentence) return [' '.join(chunk) for chunk in chunks] thematic_chunks = chunk_text_thematic(text, n_clusters=3) for i, chunk in enumerate(thematic_chunks, 1): print(f"Chunk {i}:\n{chunk}\n") - Sliding Window Chunking: Use a sliding window approach to create overlapping chunks. This method ensures that important information near the boundaries of chunks is not missed.
def chunk_text_sliding_window(text, chunk_size=200, overlap=50, unit='word'): """Chunks text using a sliding window. Args: text: The input text. chunk_size: The desired size of each chunk. overlap: The overlap between consecutive chunks. unit: The chunking unit ('word', 'char', or 'token'). Returns: A list of text chunks. """ if unit == 'word': data = text.split() elif unit == 'char': data = text else: # Implement tokenization for other units pass chunks = [] for i in range(0, len(data), chunk_size - overlap): if unit == 'word': chunk = ' '.join(data[i:i+chunk_size]) else: chunk = data[i:i+chunk_size] chunks.append(chunk) return chunks -
Content-Aware Chunking: This advanced method involves using more sophisticated NLP techniques to chunk the text based on its content and structure. Content-aware chunking can take into account factors such as topic continuity, coherence, and discourse markers. It aims to create chunks that are not only manageable but also meaningful and contextually rich.
Example of Content-Aware Chunking using Sentence Transformers:
from sentence_transformers import SentenceTransformer, util def content_aware_chunking(text, max_chunk_size=200): model = SentenceTransformer('all-MiniLM-L6-v2') sentences = nltk.sent_tokenize(text) embeddings = model.encode(sentences, convert_to_tensor=True) clusters = util.community_detection(embeddings, min_community_size=1) chunks = [] for cluster in clusters: chunk = ' '.join([sentences[i] for i in cluster]) if len(chunk.split()) <= max_chunk_size: chunks.append(chunk) else: sub_chunks = chunk_text_fixed_length(chunk, max_chunk_size) chunks.extend(sub_chunks) return chunks -
Recursive Chunking: Recursive chunking involves repeatedly breaking down chunks into smaller sub-chunks until each chunk meets a desired size or level of detail. This method ensures that very large texts are reduced to manageable and meaningful units at each level of recursion, making it easier to process and retrieve information.
Example of Recursive Chunking: ```python def recursive_chunk(text, max_chunk_size): “"”Recursively chunks text into smaller chunks.
Args: text: The input text. max_chunk_size: The maximum desired chunk size.
Returns: A list of text chunks. “””
if len(text) <= max_chunk_size: return [text]
# Choose a splitting point based on paragraphs, sentences, or other criteria # For example: paragraphs = text.split(‘\n\n’) if len(paragraphs) > 1: chunks = [] for paragraph in paragraphs: chunks.extend(recursive_chunk(paragraph, max_chunk_size)) return chunks else: # Handle single paragraph chunking, e.g., by sentence splitting # …
# …
8. **Agentic Chunking**: Agent chunking is a sophisticated technique that involves using an LLM to dynamically determine chunk boundaries based on the content and context of the text. Below is an example of a prompt example for Agentic Chunking
**Example Prompt**:
``` Prompt
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
## You are an agentic chunker. You will be provided with a content.
Decompose the content into clear and simple propositions, ensuring they are interpretable out of context.
1. Split compound sentence into simple sentences. Maintain the original phrasing from the input whenever possible.
2. For any named entity that is accompanied by additional descriptive informaiton separate this information into its own distinct proposition.
3. Decontextualize proposition by adding necessary modifier to nouns or entire sentence and replacing pronouns (e.g. it, he, she, they, this, that) with the full name of the entities they refer to.
4. Present the results as list of strings, formatted in JSON
<|eot_id|><|start_header_id|>user<|end_header_id|>
Here is the content : {content}
strictly follow the instructions provided and output in the desired format only.
<|eot_id|><|start_header_id|>assistant<|end_header_id|>
Chunk Size and Overlapping in Chunking
Determining the appropriate chunk size and whether to use overlapping chunks are critical decisions in the chunking process. These factors significantly impact the efficiency and effectiveness of the retrieval and generation stages in RAG systems.
Chunk Size
- Choosing Chunk Size: The ideal chunk size depends on the specific application and the nature of the text. Smaller chunks can provide more precise context but may miss broader information, while larger chunks capture more context but may introduce noise or irrelevant information.
- Small Chunks: Typically 100-200 words. Suitable for fine-grained retrieval where specific details are crucial.
- Medium Chunks: Typically 200-500 words. Balance between detail and context, suitable for most applications.
- Large Chunks: Typically 500-1000 words. Useful for capturing broader context but may be less precise.
- Impact of Chunk Size: The chunk size affects the retrieval accuracy and computational efficiency. Smaller chunks generally lead to higher retrieval precision but may require more chunks to cover the same amount of text, increasing computational overhead. Larger chunks reduce the number of chunks but may lower retrieval precision.
Overlapping Chunks
-
Purpose of Overlapping: Overlapping chunks ensure that important information near the boundaries of chunks is not missed. This approach is particularly useful when the text has high semantic continuity, and critical information may span across chunk boundaries.
- Degree of Overlap: The overlap size should be carefully chosen to balance redundancy and completeness. Common overlap sizes range from 10% to 50% of the chunk size.
- Small Overlap: 10-20% of the chunk size. Minimizes redundancy but may still miss some boundary information.
- Medium Overlap: 20-30% of the chunk size. Good balance between coverage and redundancy.
- Large Overlap: 30-50% of the chunk size. Ensures comprehensive coverage but increases redundancy and computational load.
- Example of Overlapping Chunking:
def chunk_text_sliding_window(text, chunk_size=200, overlap=50): words = text.split() chunks = [] for i in range(0, len(words), chunk_size - overlap): chunk = words[i:i + chunk_size] chunks.append(' '.join(chunk)) return chunks
Evaluating the Performance of Chunking
Evaluating the performance of chunking is crucial to ensure that the chosen method effectively enhances the retrieval and generation processes. Here are some key metrics and approaches for evaluating chunking performance:
Retrieval Metrics
- Precision@K: Measures the proportion of relevant chunks among the top K retrieved chunks.
def precision_at_k(retrieved_chunks, relevant_chunks, k): return len(set(retrieved_chunks[:k]) & set(relevant_chunks)) / k - Recall@K: Measures the proportion of relevant chunks retrieved among the top K chunks.
def recall_at_k(retrieved_chunks, relevant_chunks, k): return len(set(retrieved_chunks[:k]) & set(relevant_chunks)) / len(relevant_chunks) - F1 Score: Harmonic mean of Precision@K and Recall@K, providing a balance between precision and recall.
def f1_score_at_k(precision, recall): if precision + recall == 0: return 0 return 2 * (precision * recall) / (precision + recall) - MAP : Mean Average Precision (MAP) is primarily used in information retrieval and object detection tasks to evaluate the ranking of retrieved items
import numpy as np def calculate_ap(y_true, y_score): """Calculates average precision for a single query. Args: y_true: Ground truth labels (0 or 1). y_score: Predicted scores. Returns: Average precision. """ # Sort y_score and corresponding y_true in descending order y_score, y_true = zip(*sorted(zip(y_score, y_true), key=lambda x: x[0], reverse=True)) correct_hits = 0 sum_precision = 0 for i, y in enumerate(y_true): if y == 1: correct_hits += 1 precision = correct_hits / (i + 1) sum_precision += precision return sum_precision / sum(y_true) def calculate_map(y_true, y_score): """Calculates mean average precision. Args: y_true: Ground truth labels (list of lists). y_score: Predicted scores (list of lists). Returns: Mean average precision. """ aps = [] for i in range(len(y_true)): ap = calculate_ap(y_true[i], y_score[i]) aps.append(ap) return np.mean(aps) - NDCG: NDCG is a metric used to evaluate the quality of a ranking of items. It measures how well the most relevant items are ranked at the top of the list. In the context of chunking, we can potentially apply NDCG by ranking chunks based on a relevance score and evaluating how well the most relevant chunks are placed at the beginning of the list.
import numpy as np
def calculate_dcg(rel):
"""Calculates Discounted Cumulative Gain (DCG).
Args:
rel: Relevance scores of items.
Returns:
DCG value.
"""
return np.sum(rel / np.log2(np.arange(len(rel)) + 2))
def calculate_idcg(rel):
"""Calculates Ideal Discounted Cumulative Gain (IDCG).
Args:
rel: Relevance scores of items.
Returns:
IDCG value.
"""
rel = np.sort(rel)[::-1]
return calculate_dcg(rel)
def calculate_ndcg(rel):
"""Calculates Normalized Discounted Cumulative Gain (NDCG).
Args:
rel: Relevance scores of items.
Returns:
NDCG value.
"""
dcg = calculate_dcg(rel)
idcg = calculate_idcg(rel)
return dcg / idcg
# Example usage
relevance_scores = [3, 2, 1, 0]
ndcg_score = calculate_ndcg(relevance_scores)
print(ndcg_score)
Generation Metrics
- BLEU Score: Measures the overlap between the generated text and reference text, considering n-grams.
from nltk.translate.bleu_score import sentence_bleu def bleu_score(reference, generated): return sentence_bleu([reference.split()], generated.split()) - ROUGE Score: Measures the overlap of n-grams, longest common subsequence (LCS), and skip-bigram between the generated text and reference text.
from rouge import Rouge rouge = Rouge() def rouge_score(reference, generated): scores = rouge.get_scores(generated, reference) return scores[0]['rouge-l']['f'] - Human Evaluation: Involves subjective evaluation by human judges to assess the relevance, coherence, and overall quality of the generated responses. Human evaluation can provide insights that automated metrics might miss.
Chunking Alternatives
While chunking is an effective method for improving the efficiency and effectiveness of RAG systems, there are alternative techniques that can also be considered:
-
Hierarchical Indexing: Instead of chunking the text, hierarchical indexing organizes the data into a tree structure where each node represents a topic or subtopic. This allows for efficient retrieval by navigating through the tree based on the query’s context. ```python class HierarchicalIndex: def init(self): self.tree = {}
def add_document(self, doc_id, topics): current_level = self.tree for topic in topics: if topic not in current_level: current_level[topic] = {} current_level = current_level[topic] current_level['doc_id'] = doc_id def retrieve(self, query_topics): current_level = self.tree for topic in query_topics: if topic in current_level: current_level = current_level[topic] else: return [] return current_level.get('doc_id', []) - Summarization: Instead of retrieving chunks, the system generates summaries of documents or sections that are relevant to the query. This can be done using extractive or abstractive summarization techniques.
from transformers import BartTokenizer, BartForConditionalGeneration def generate_summary(text): tokenizer = BartTokenizer.from_pretrained('facebook/bart-large-cnn') model = BartForConditionalGeneration.from_pretrained('facebook/bart-large-cnn') inputs = tokenizer([text], max_length=1024, return_tensors='pt', truncation=True) summary_ids = model.generate(inputs['input_ids'], num_beams=4, max_length=150, early_stopping=True) return tokenizer.decode(summary_ids[0], skip_special_tokens=True) - Dense Passage Retrieval (DPR): DPR uses dense vector representations for both questions and passages, allowing for efficient similarity search using vector databases like FAISS.
from transformers import DPRQuestionEncoder, DPRContextEncoder, DPRQuestionEncoderTokenizer, DPRContextEncoderTokenizer from sklearn.metrics.pairwise import cosine_similarity question_encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-single-nq-base") context_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base") question_tokenizer = DPRQuestionEncoderTokenizer.from_pretrained("facebook/dpr-question_encoder-single-nq-base") context_tokenizer = DPRContextEncoderTokenizer.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base") def encode_texts(texts, tokenizer, encoder): inputs = tokenizer(texts, return_tensors="pt", padding=True, truncation=True) return encoder(**inputs).pooler_output question_embeddings = encode_texts(["What is chunking?"], question_tokenizer, question_encoder) context_embeddings = encode_texts(["Chunking is a process...", "Another context..."], context_tokenizer, context_encoder) similarities = cosine_similarity(question_embeddings, context_embeddings) - Graph-Based Representations: Instead of breaking the text into chunks, graph-based representations model the relationships between different parts of the text. Nodes represent entities, concepts, or chunks of text, and edges represent the relationships between them. This approach allows for more flexible and context-aware retrieval.
import networkx as nx
def build_graph(texts):
graph = nx.Graph()
for i, text in enumerate(texts):
graph.add_node(i, text=text)
# Add edges based on some similarity metric
for j in range(i + 1, len(texts)):
similarity = compute_similarity(text, texts[j])
if similarity > threshold:
graph.add_edge(i, j, weight=similarity)
return graph
def retrieve_from_graph(graph, query):
query_node = len(graph.nodes)
graph.add_node(query_node, text=query)
for i in range(query_node):
similarity = compute_similarity(query, graph.nodes[i]['text'])
if similarity > threshold:
graph.add_edge(query_node, i, weight=similarity)
# Retrieve nodes with highest similarity
neighbors = sorted(graph[query_node], key=lambda x: graph[query_node][x]['weight'], reverse=True)
return [graph.nodes[n]['text'] for n in neighbors[:k]]
Graph-based representations can capture complex relationships and provide a more holistic view of the text, making them a powerful alternative to chunking.
Conclusion
Chunking plays a pivotal role in enhancing the efficiency and effectiveness of Retrieval-Augmented Generation systems. By breaking down large texts into manageable chunks, we can improve retrieval speed, contextual relevance, scalability, and the overall quality of generated responses. Evaluating the performance of chunking methods involves considering retrieval and generation metrics, as well as efficiency and cost metrics. As NLP continues to advance, techniques like chunking will remain essential for optimizing the performance of RAG and other language processing systems. Additionally, exploring alternatives such as hierarchical indexing, passage retrieval, summarization, dense passage retrieval, and graph-based representations can further enhance the capabilities of RAG systems.
Embark on your journey to harness the power of chunking in RAG and unlock new possibilities in the world of Natural Language Processing!
If you found this blog post helpful, please consider citing it in your work:
@misc{malaikannan2024chunking, author = {Sankarasubbu, Malaikannan}, title = {Breaking Down Data: The Science and Art of Chunking in Text Processing & RAG Pipeline}, year = {2024}, url = {https://malaikannan.github.io/2024/08/05/Chunking/}, note = {Accessed: 2024-08-12} }