Natural Language Processing using Word2Vec
22 Jan 2017Natural Language Processing is a complicated area. Computers are really good at crunching numbers but not so much with text. We have to specifically instruct them on how to handle text. For Text analytics to be carried out we have to represent text in a form the computers can understand i.e. in the form of numbers.
- The method for doing this varies.
- A good method is one that captures as much of the meaning of the text as possible.
After this is done, analysis can be carried out on these numbers in the same way as dealing with numbers.
Conventional Text Analysis or Bag of Word Models
Lets take this example text “SanFrancisco is a beautiful California city. LosAngeles is a lovely California metropolis”
Popular way of converting this text to numbers is known as “Bag of Words” model. Each word is extracted from the text and put in a bag together.Each word in the bag is then assigned a suitable value. Lets parse the example text and extract words
“SanFrancisco”, “is”, “a”, “city”, “LosAngeles” ,”lovely”, “California”, “metropolis”.
Stop words are the most common words in a language. In the extracted list of words “is” , “a” are considered stop words hence it will be ignored. So the final list of extracted words will be
“SanFrancisco”, “beautiful”, “city” ,”LosAngeles”, “lovely” , “California” , “metropolis”
In Bag of Words model each word is assigned a value based on number of times it occurs in the text.
| SanFrancisco | beautiful | city | LosAngeles | lovely | California | metropolis |
|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 2 | 1 |
This approach has lot of disadvantages, few of those are listed below
- It does not capture the order of words in the original text.
- It does not capture the context of the text.
- It does not capture about the meanings of the words.
What we are telling the computer using this approach is city, lovely, metropolis are all equal. Even though city and metropolis are equivalent and lovely is something very different.
Neural Language models
Prof Yoshua Bengio started this work in 2008. A language model is an algorithm for capturing the salient statistical characteristics of the distribution of sequences of words in a natural language.
A neural language model learn distributed representations on words to reduce the impact of the curse of dimensionality. Curse of dimensionality is when number of input variable grows the number of required examples to train a model grows exponentially.
You can read more about this work in this link
Word2vec – Word to Vector
Word2Vec is one of the influential papers in Natural Language Processing. It has nearly 3000 citations. Word2Vec improves on Prof Yoshua Bengio’s earlier work on Neural Language Models. Word2Vec was created by google, with main author being Tomas Mikolov. You can read the original paper here.
Word2vec is an answer to all the disadvantages listed in the previous section.
- It is intelligent, learns context of the text.
- Understands sentences, and not just individual words.
- Understands relationships between words.
We understand what a word is, lets see what a vector is. A vector is a sequence of numbers that forms a group. For example
- (3) is a one dimensional vector.
- (2,8) is a two dimensional vector.
- (12,6,7,4) is a four dimensional vector.
A vector can be represented as by plotting on a graph. Lets take a 2D example
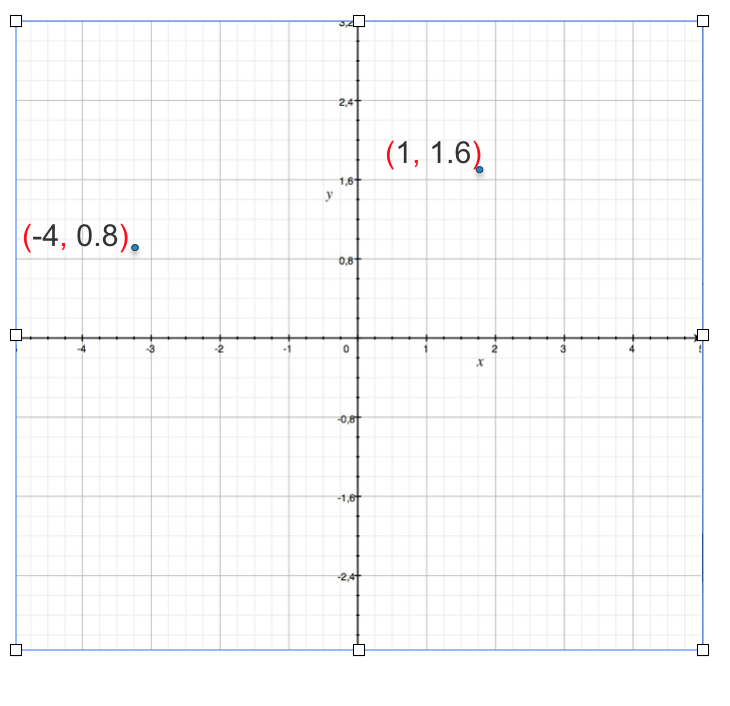
We can only 3 dimensions, anything more than that you can just say it not visualize.
How Word2Vec works
For a input text it looks at each word and the context of words around it. It trains on the text, and recognizes the order of each word, and the structure of the sentences. At the end of training each word is represented by a vector of N (mostly in 100 to 300 range) dimension.
When we train word2vec algorithm in the example discussed above “SanFrancisco is a beautiful California city. LosAngeles is a lovely California metropolis”
Lets assume that it outputs 2 dimension vectors for each words, since we can’t visualize anything more than 3 dimension.
- SanFrancisco (6,6)
- beautiful (-13,-4)
- California (10,8)
- city (2,10)
- LosAngeles (6.5,5)
- lovely(-12,-7)
- metropolis(2.5,8)
Below is a 2D Plot of vectors
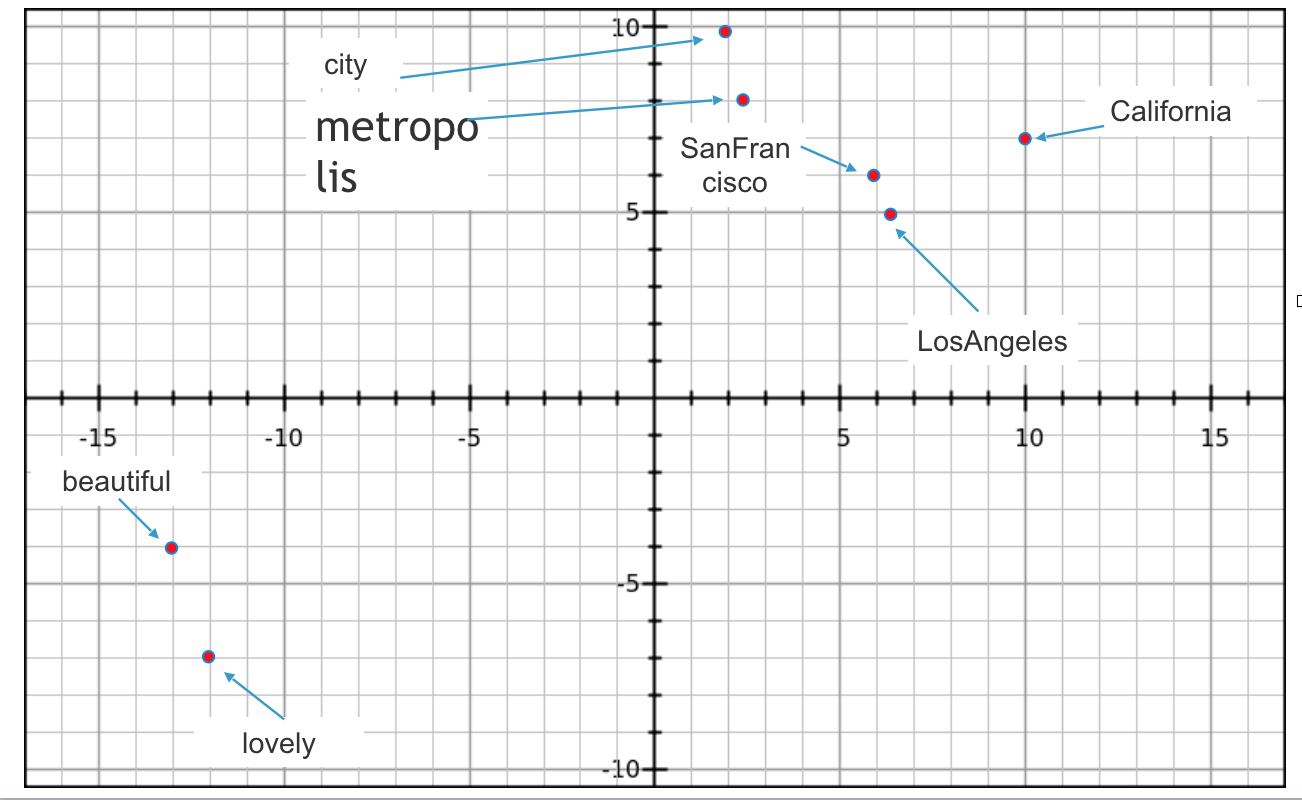
You can see in the image that Word2vec algorithm inferred from the input text. SanFrancisco and LosAngeles are grouped together. Beautiful and lovely are grouped together. City and metropolis are grouped together. Beauty about this is, Word2vec deduced this purely from data, without being explicitly taught english or geography.
Word2vec and Analogies
Word2vec algorithm is really good in discovering analogies on data. In the below plot from relative position analogies can be observed.
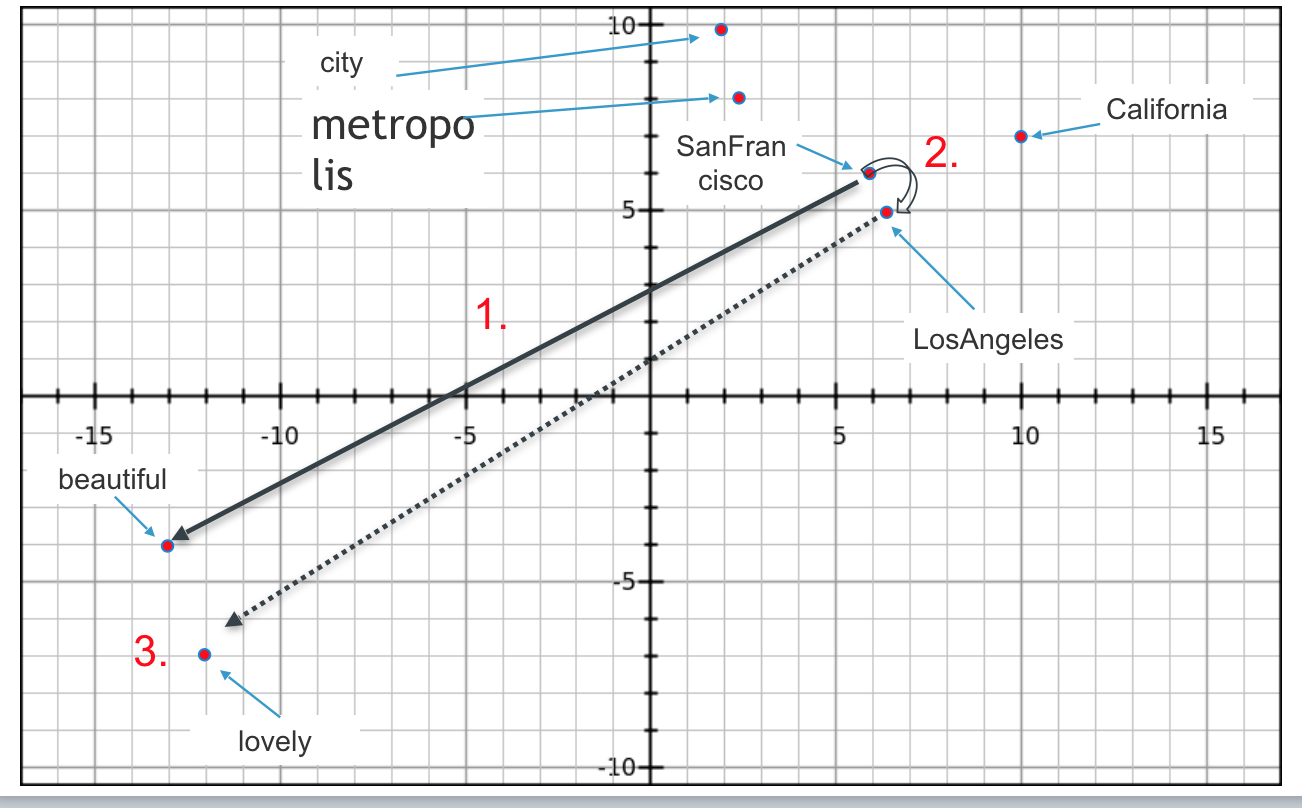
Algorithm knows the answer to
- If SanFrancisco : beautiful
- then LosAngeles : ???
Answer : lovely
To get to the answer do
- Draw a line from SanFrancisco to beautiful
- Shift this line to LosAngeles
- Find the end-point of this line.
Similarly you can draw other analogies like
- if SanFrancisco : city
- then LosAngeles : metropolis
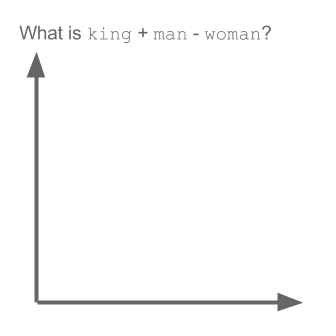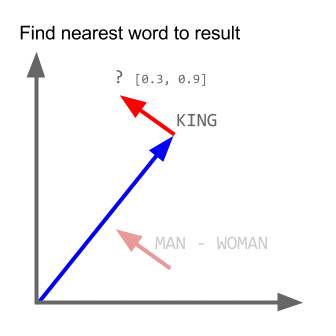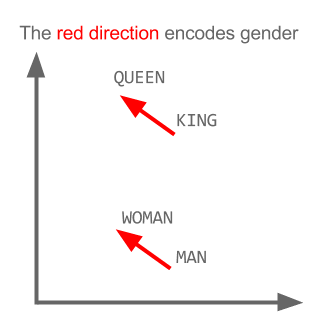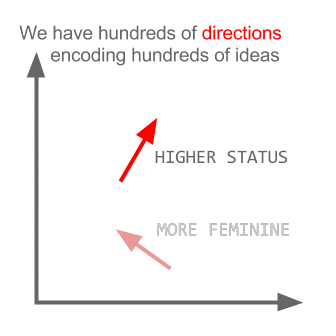
Math for Analogies is beautiful, it can be expressed in simple vector arithmetic.
- SanFrancisco - LosAngeles = beautiful - [unknown]
- [unknown] = beautiful + LosAngeles - SanFrancisco
- [unknown] = (-12.5,5) which is close to lovely

Google trained Word2Vec on a large volume data, it came up with some interesting analogies
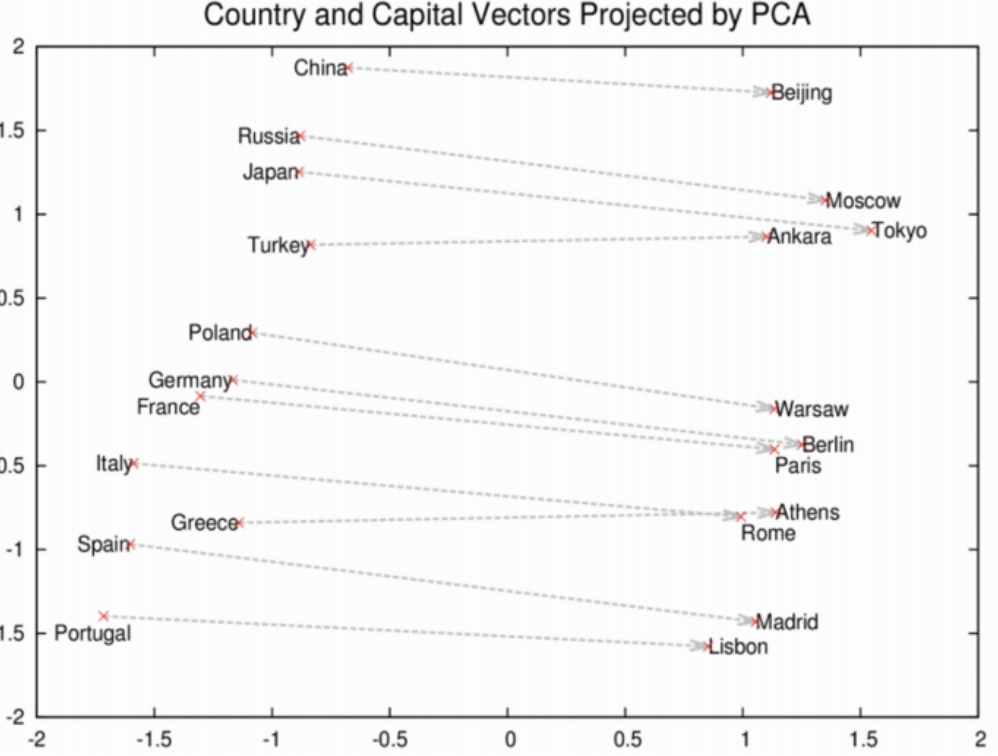
countries and capitals
Word2vec depicting relationships between countries and capitals
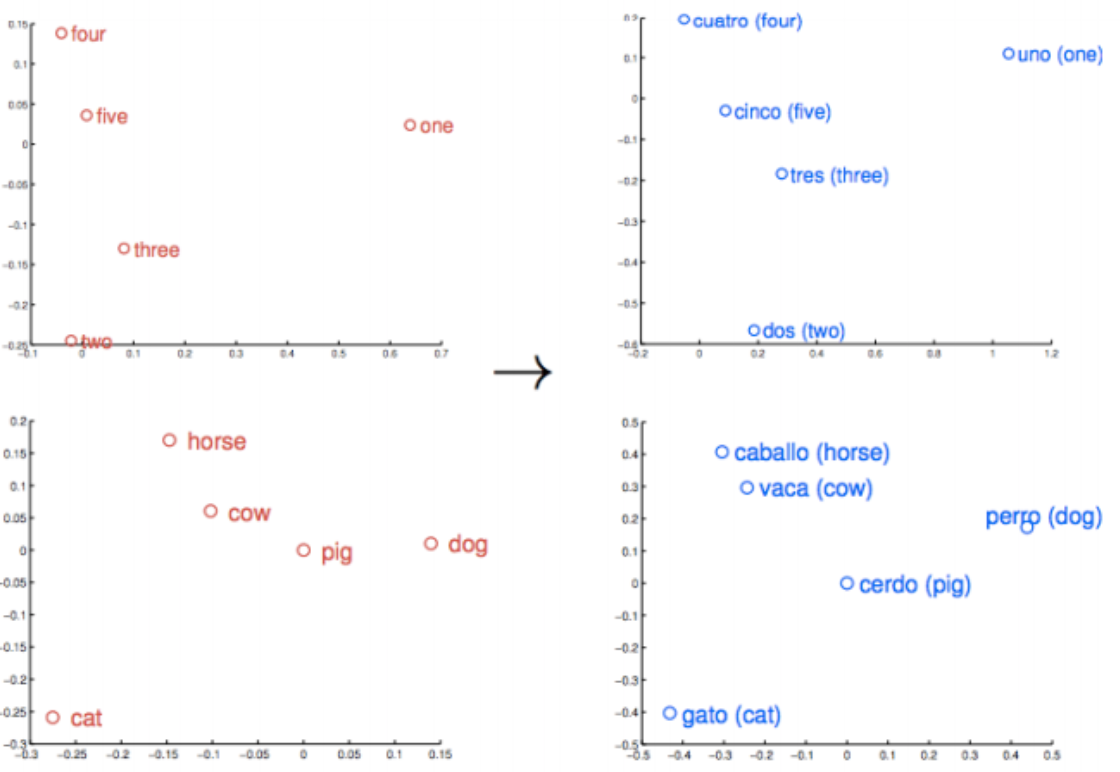
Machine translation
In complicated use-cases models can understand translations from one language to another.
Contributions
Thanks to Arthur Chan for suggesting changes to the blog.